How It Works
VOCL captures electrical signals from facial muscles during attempted speech—even without vocalization—and translates them into words.
Calibration
Users complete a 10-minute personalization sequence, attempting 20 common phonemes. Our adaptive algorithms learn each user's unique muscle activation patterns, accounting for variations in anatomy and condition.
Signal Capture
When users attempt to speak, voltage drops as subtle as 5 microvolts run across facial muscles. Our 8 gold cup electrodes measure these signals from key speech muscles—the orbicularis oris and depressor labii inferioris.
AI Decoding
Our CNN-LSTM pipeline recognizes individual phonemes and predicts words. LLM integration provides context-aware error correction, producing natural output with under 300ms latency.
Why EMG?
EMG signals from attempted speech are 3-5× stronger than imagined speech signals—rendering brain surgery obsolete while delivering natural, non-invasive communication.
Who We're Building For
Patients who retain residual control of their facial muscles but cannot vocalize.
ALS Patients
Individuals in early-to-mid stage ALS who retain motor planning ability. As Dr. Sergey Stavisky noted, "Non-invasive signals can definitely serve early stage ALS patients who still retain residual movement ability."
Stroke Survivors
Post-stroke dysarthria patients who understand language fully but struggle to produce it. Speech loss is the driving force for depression in 64% of stroke survivors.
Dysarthria & Aphasia
Progressive conditions affecting speech muscle control—from Parkinson's to MS—where the brain's speech commands remain intact but neuromuscular execution fails.
Scientific Validation
Neural pattern consistency across attempted speech and silent conditions.
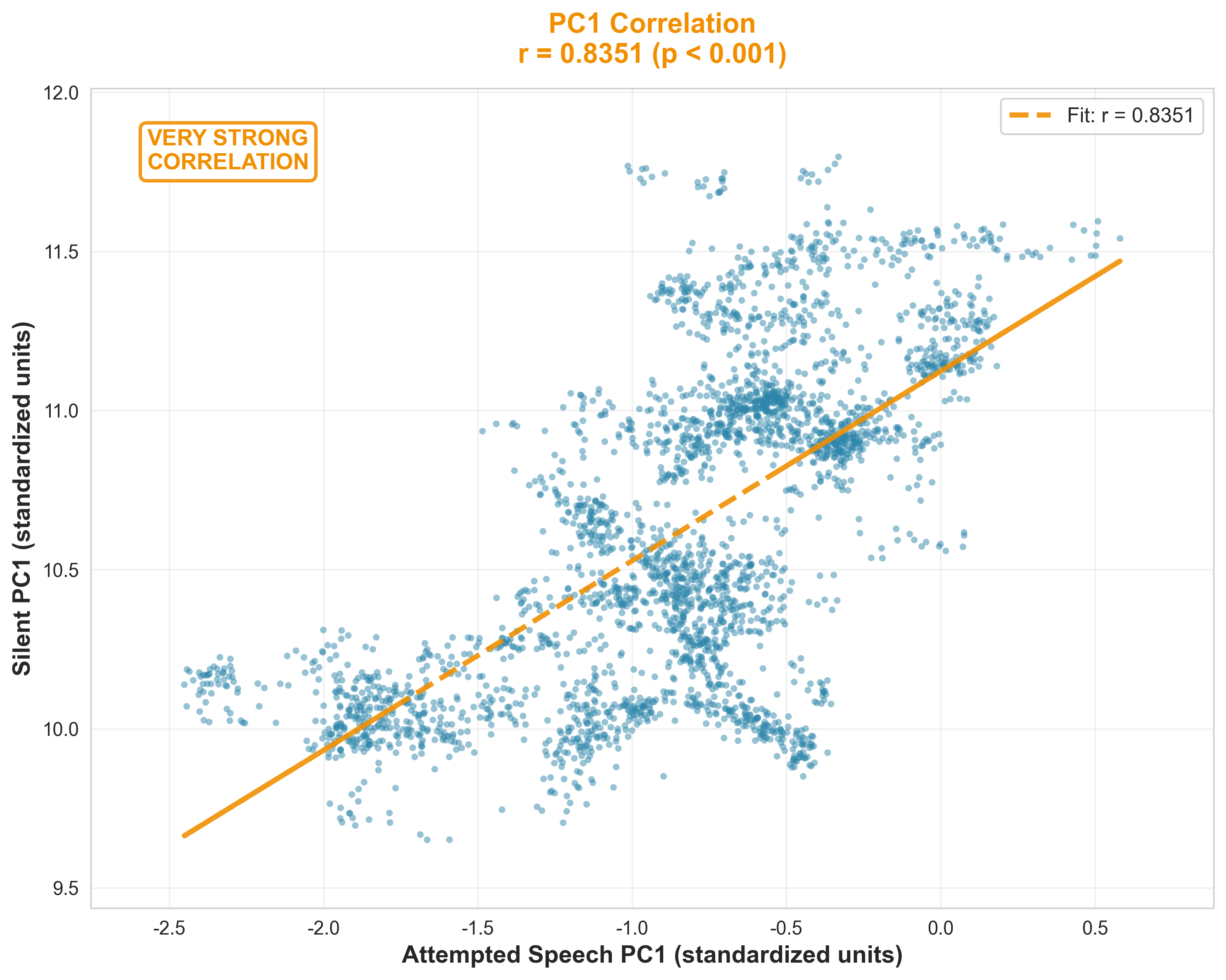
PC1 Correlation Analysis
PC1 Correlation (r = 0.84)
TL;DR
When people attempt to speak (even silently), their brain shows the same patterns whether they vocalize or not. This correlation of 0.84 means the neural signals are nearly identical—proving VOCL can decode speech without requiring actual vocalization.
In-Depth Analysis
Principal Component Analysis (PCA) is a dimensionality reduction technique that identifies the most significant patterns in complex neural data. Principal Component 1 (PC1) represents the dominant source of variance—essentially capturing the primary neural signal driving the observed brain activity.
In this analysis, we compared PC1 values extracted from EEG recordings during two conditions: (1) attempted speech with vocalization, and (2) silent subvocalization (attempted speech without sound). The Pearson correlation coefficient of r = 0.84 indicates a strong positive linear relationship between these conditions.
This finding is significant because it demonstrates that the neural mechanisms underlying speech production remain consistent regardless of whether motor execution (vocal cord activation) occurs. The brain generates similar activation patterns whether the user produces audible speech or merely attempts to speak silently—validating the core principle behind VOCL's non-invasive approach.
Key Findings:
- PC1 captures dominant brain activity: The first principal component accounts for the largest proportion of variance in neural signals, representing the primary cognitive-motor pathway involved in speech planning and execution.
- Synchronous activation: PC1 activity increases synchronously in both vocalized and silent conditions, indicating that the neural command structure is preserved even when motor output is suppressed.
- Pattern consistency: Neural patterns remain consistent across conditions, suggesting that speech intent can be decoded from brain signals alone, without requiring actual vocalization—a critical finding for non-invasive assistive technology.
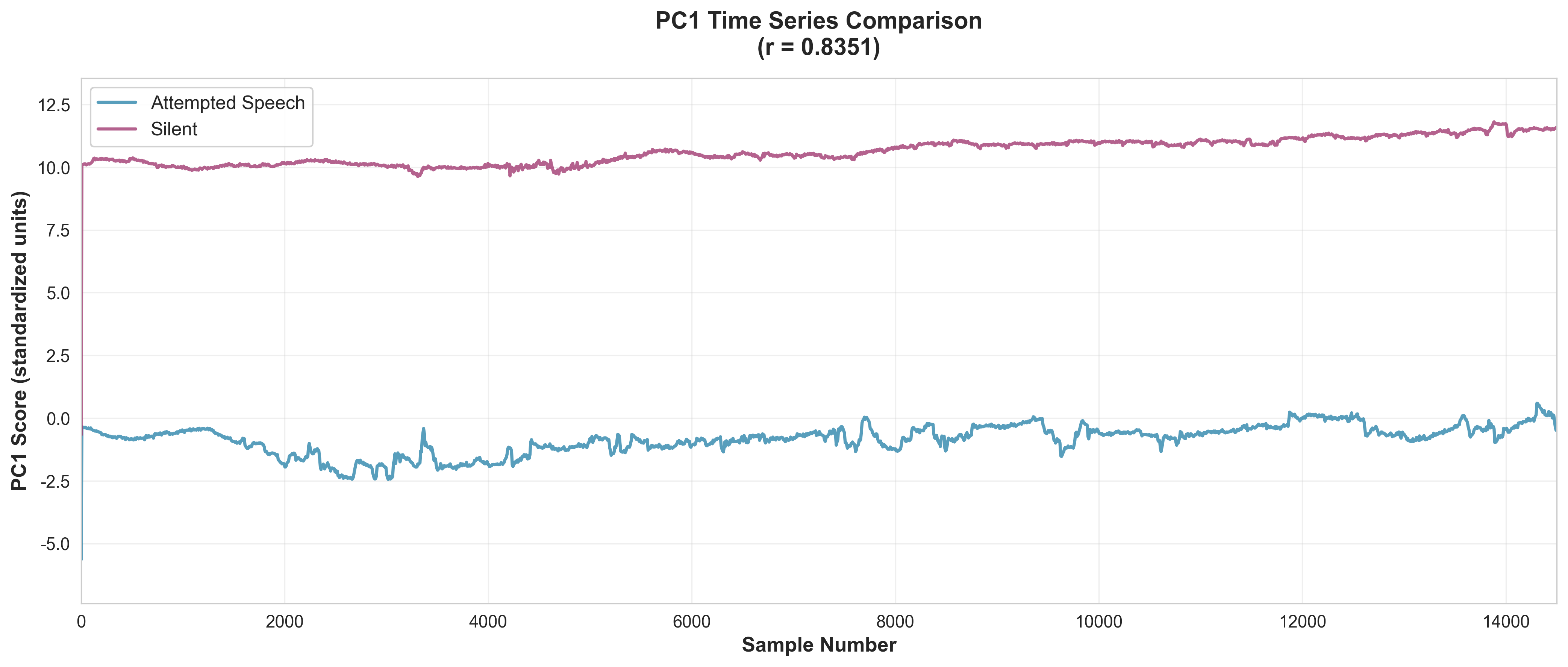
PC1 Timeseries Analysis
Temporal Dynamics
TL;DR
Over time, brain signals follow the same trajectory whether someone speaks aloud or silently. This temporal consistency proves that VOCL can reliably track speech patterns in real-time, making continuous communication possible.
In-Depth Analysis
While correlation analysis reveals the relationship between conditions at a single point in time, timeseries analysis examines how neural signals evolve dynamically throughout the speech production process. This temporal perspective is crucial for understanding whether neural patterns remain consistent not just in magnitude, but also in their sequence and timing.
The timeseries visualization plots PC1 values as a function of time, comparing the temporal evolution of neural activity during attempted speech (with vocalization) versus silent subvocalization. The overlapping trajectories demonstrate that both conditions follow remarkably similar temporal patterns—the signals rise and fall in near-perfect synchrony.
This temporal consistency has profound implications for real-world application. It suggests that VOCL can decode speech intent continuously, tracking the user's neural activity as they form words and sentences in real-time. The stability of these patterns across conditions indicates that the system can maintain accuracy even when users cannot produce audible speech—exactly the scenario faced by individuals with ALS, dysarthria, or other speech-impairing conditions.
Implications:
- Signal stability: Neural signals remain stable and predictable across both vocalized and silent conditions, enabling reliable decoding algorithms that don't depend on motor execution.
- Temporal validation: The consistent temporal patterns validate the correlation findings, demonstrating that the relationship holds not just statistically, but dynamically throughout the speech production process.
- Real-time feasibility: The predictable temporal structure supports the feasibility of real-time, non-invasive speech decoding, making continuous communication possible for users who cannot vocalize.